
Foundations and misconceptions surrounding big data
The problems that motivate our thinking about technology change so quickly and dramatically that it can be hard to keep track of them. For instance, one could be forgiven for thinking that we’ve always been in danger of running out of data if they’ve paid attention to some of the recent developments at the frontiers of AI research. This hasn’t always been the case. Only a few short years ago, “big data” was on everyone’s minds and we were coming to terms with how to manage the vast quantities of data being produced each and every day. It’s difficult to think of a better example of this than the one provided by earth observation and remote sensing: NASA’s Landsat 7 satellite network alone produces hundreds of gigabytes per day.


This almost unbelievable explosion of data is one of the key motivations for GeoTrellis, a project I’ve been fortunate enough to work on with some of the brightest and most talented people I’ve ever known. GeoTrellis provides a set of high-level facilities for working with geospatial data at the scale that it is produced. It has its own GeoTiff reader written in pure Scala and requires nothing outside the JVM (it is actually very performant!) but it also allows users to lean on the battle-tested native library, GDAL through a set of bindings we’ve written. GDAL is used across industries by players both big and small where geospatial raster data is found and it supports a wide range of different formats.
Before getting into some exciting new opportunities that we’ve recently unlocked, it might be worth considering where ‘big data’ is today and how we got here. To that end, we will briefly discuss the history of modern ‘Big Data’ with a focus on the developments that have made access cheaper and easier for smaller and smaller organizations. After that, we’ll look at specific issues encountered as I tried to enable GDAL on EMR-Serverless.
Data processing at scale and the rise of EMR-Serverless
The fact that the problem of ‘too much data’ has receded from popular consciousness is – the pessimist will note – a reflection of the tech world’s tendency to fall into a predictable hype cycle. At the same time, it is the result of steady progress in the commodification and democratization of tools and techniques that have made many of these problems tractable. As recently as the early 1990s, extremely expensive supercomputers with proprietary hardware were the sole means by which large-scale problems could be approached. It was simply too expensive for most organizations to take advantage of the potential benefits offered by processing at scale. This began to change towards the end of that decade as companies like Amazon and Google adopted a completely different strategy: scale compute up across commodity hardware that was widely available and relatively inexpensive.
An early strategy, suited to the limitations of existing hardware, was MapReduce. The idea is simple enough to be stated in one sentence: spread out work that can be handled separately across many computers (map) and collect the results for analysis and further refinement (reduce). As hardware limitations softened over time and computers with larger stores of RAM became cheaper and more widely available, new strategies for describing and carrying out large-scale data processing were developed. Apache Spark is one such advance and where MapReduce suffered from the costs of writing results to disk after each processing step, Spark opted to keep as much as possible in the much faster ‘working memory’ of RAM which was becoming increasingly abundant. This shift translated directly into greater speed and flexibility which has become widely available.
This truly fast, truly ‘Big’ compute enabled by Spark is only half of the story though. While the software was improving, so too were the resources available for building out or ‘spinning up’ the machine clusters necessary to actually execute the work Spark could describe. In 2009, AWS released its first major offering suitable for quickly deploying virtual machines running in concert for executing such large-scale distributed workloads: EMR. Before EMR, the overhead of orchestrating separate machines was a significant burden, requiring any organizations hoping to deploy their own ‘big data’ jobs to have, in house, both operations and software expertise. With EMR, many of the difficulties related to spinning up hardware, ensuring all dependencies were installed across all machines, and enabling the requisite networking for these processes became far simpler.
Still, properly deploying EMR requires a clear understanding of the way that Spark processes are executed. There remain non-trivial costs associated with actually deploying these large clusters. Experience has proven that it can still be tricky to efficiently provision all and only the resources required. Custom execution environments can be a pain point as working with bootstrap scripts or custom AMIs is far from the best developer experience. Worse, workloads that require variable quantities of hardware – and this is very often the case – implicate some of the same skills that have historically made it so difficult for smaller organizations to justify ‘big data’ work.
Enter EMR-Serverless. Without trying to be hyperbolic, I think it is safe to say that the pain points mentioned above which have often been prohibitive for smaller teams are becoming a thing of the past. With EMR-Serverless, it is now possible to build custom execution environments entirely within docker. Best of all, the time-consuming and headache-inducing process of managing cluster sizes has almost entirely been abstracted away. You can actually – really! – let AWS manage scaling compute up and down in response to your workload. It appears to me, having spent years working with these distributed systems, that we are entering a future in which these cutting-edge distributed technologies are both widely available and economically viable. In our attempts to compare EMR and EMR-Serverless, we’ve seen reductions in time spent worrying about resource provisioning, time spent running jobs, and – despite what we expected when starting this work – even total cost per job.
Deploying custom images with EMR-Serverless
If the previous section reads like ad-copy that’s because I think EMR-Serverless is genuinely a game-changer for organizations big and small that have complicated, large data processing challenges. Still, software is hard and even the most robust systems depend on people taking the time to carefully think from first principles when things go awry. The rest of this essay will deal with a real-world difficulty I encountered while trying to make GDAL work in a custom execution environment for EMR-Serverless. My hope is that it provides some insight into the process of open source software development, helps others avoid similar pitfalls, and maybe even brings down some barriers preventing the kind of large-scale processing demanded by the continued proliferation of earth observation technologies.
As mentioned in the introduction, GeoTrellis is a library focused on providing high level interfaces for working with geospatial data. It is capable of reaching outside the JVM to use GDAL when reading rasters. Given GDAL’s popularity, its stability, and its support for a wide range of formats, it was only natural that when building out a custom execution environment for working with geospatial data on EMR-Serverless, we would provide a lightweight, built-from-scratch docker image with the required linked libraries set up for easy discovery.
Luckily, a few very patient and talented engineers had worked out many of the steps that this would require. If you’re looking to make sense of the not-entirely-pleasant process of building GDAL with CMake in the context of Amazon Linux 2 (AL2) or RHEL7, I know of no better resource than docker-lambda.


With a solid example of what the build would require and a few hours navigating the slight differences of environment between AL2 and the base image amazon provides for customizing EMR-Serverless environments, I was running GDAL commands inside a customized container on my machine. Note that customized images of this sort will need to conform to a set of tests amazon has provided that may be useful for local testing and CI. One requirement is that the docker image’s entrypoint is directed to the provided script at `/usr/bin/entrypoint.sh`. To explore the contents of this custom image locally while circumventing this requirement, it is thus recommended to specify a custom entrypoint at runtime: `run -it --entrypoint="/bin/bash" "${IMAGE_NAME}:latest"`
Here, it might be useful to describe the process of deploying our custom image. To avoid getting bogged down in details that are better explored through the documentation provided by AWS, I’ll lay out the steps very briefly:
1. Deploy the custom image to AWS Elastic Container Repository (ECR)
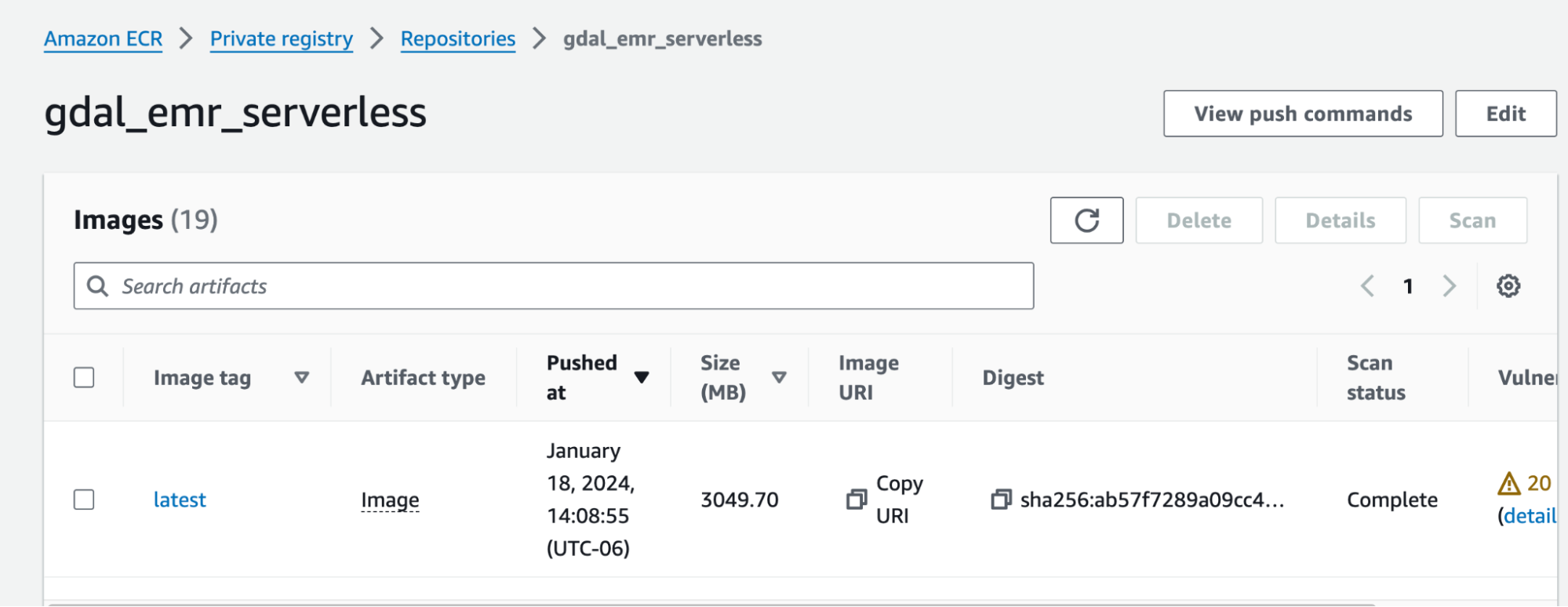
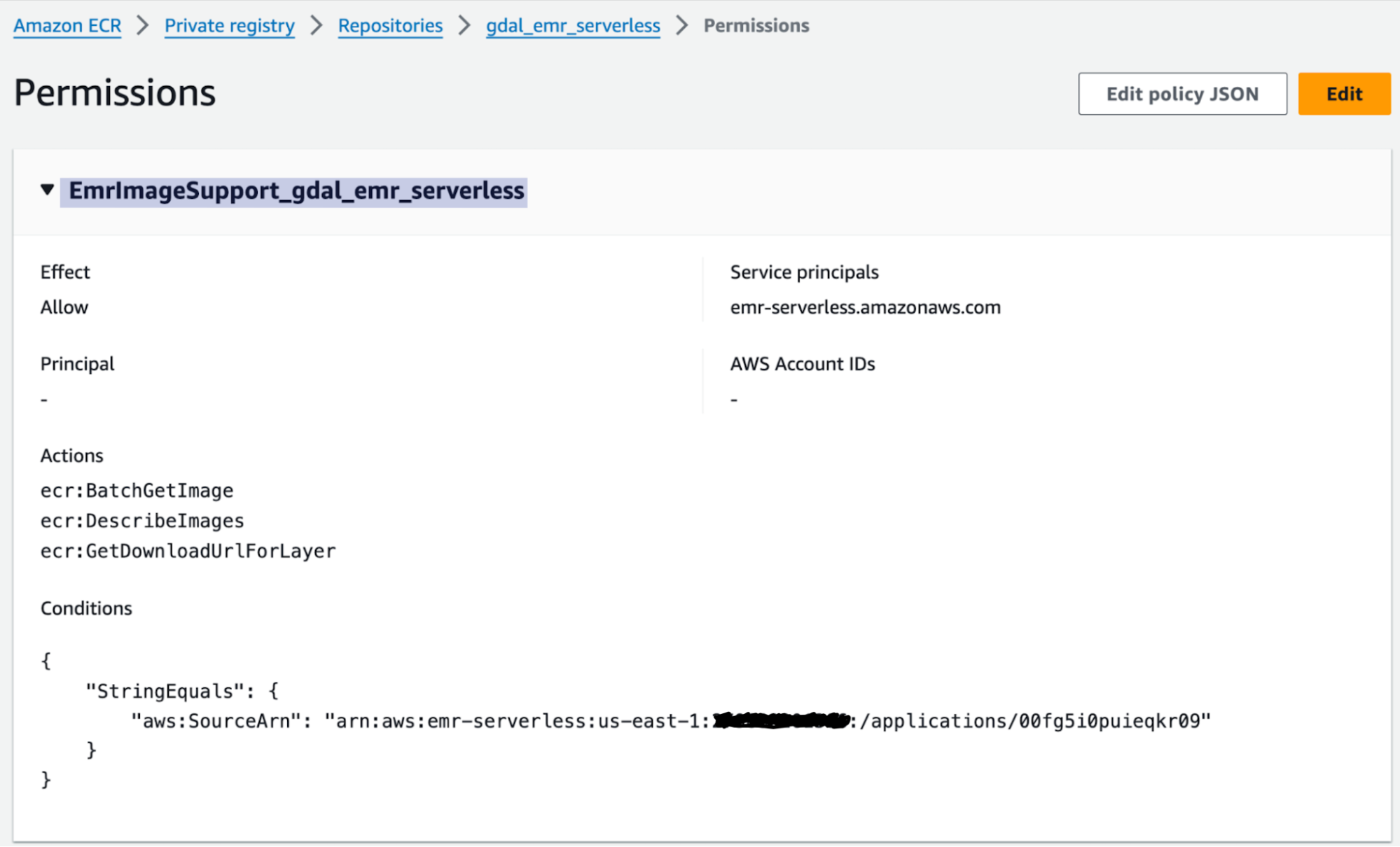
2. Set up the permissions in ECR necessary for EMR-Serverless to access ECR’s images
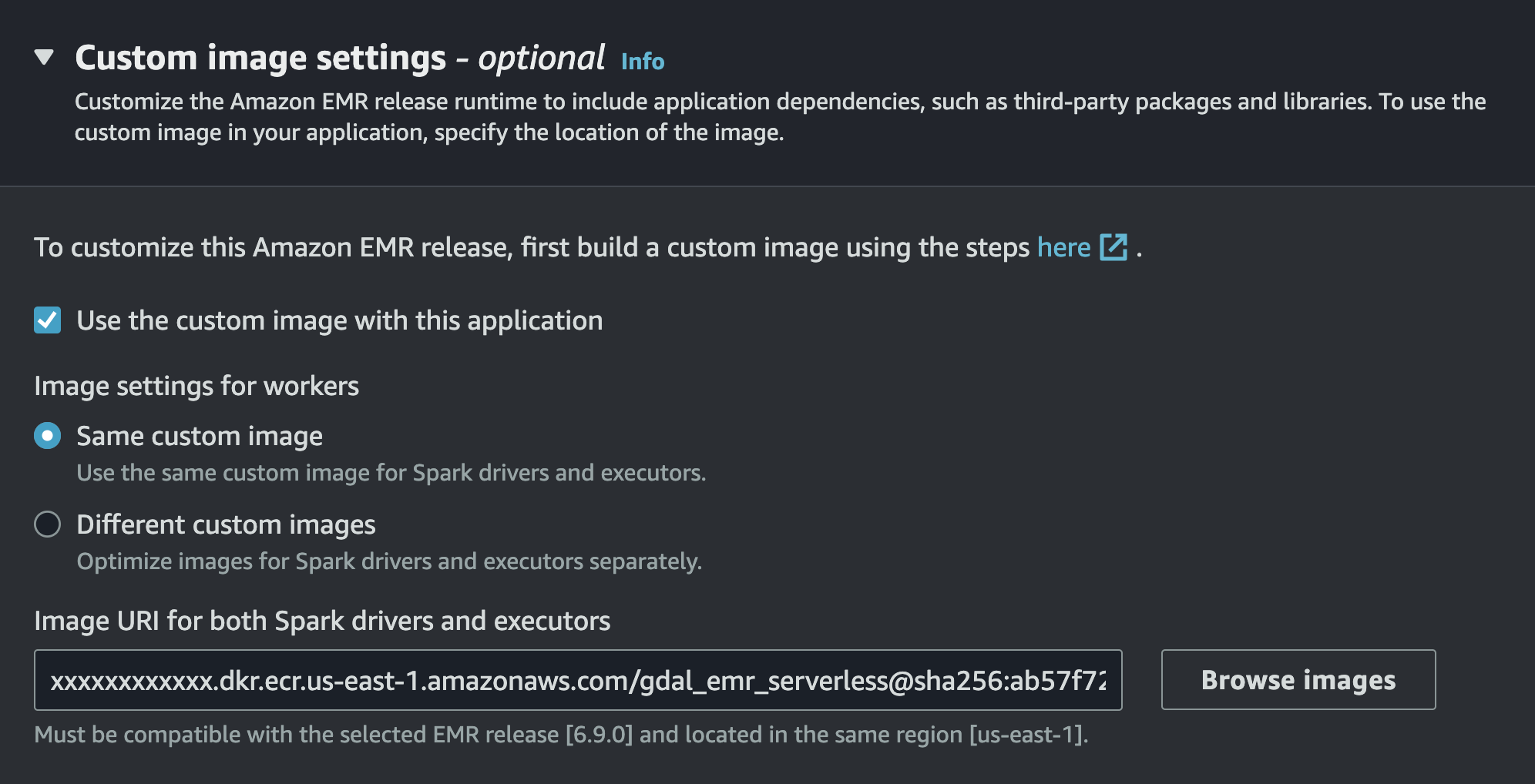
3. When configuring the EMR-Serverless application destined to run this custom image, specify the custom container which will serve as your execution environment
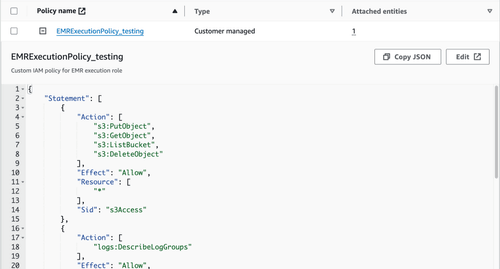
4. Ensure that the necessary permissions for accessing external resources, such as S3, are provided via IAM so that when GDAL uses the credential provider chain, it is able to access said resources. The example below should be suitable for reading objects on S3; don’t forget to set up the appropriate ‘Trust relationship’ for `emr-serverless.amazonaws.com` to assume this role.

At this point, the custom image should have been ready to accept jobs that expect GDAL to be available on all of the cluster’s nodes. This gist is a simple program I used to verify things were working. Of course, things weren’t working. Jobs kept erroring out with complaints of insufficient permissions regardless of how much I elevated permissions or attempted to read from permissive, public buckets. If you’ve worked with GDAL, you can probably guess what I did next: I assumed that there was some step I must have been missing because when GDAL fails it is a matter of near certainty that the user screwed something up. I really trust GDAL. Google Maps trusts GDAL! It generally just works.
So, lacking much in the way of insight, the next step was to enable as many logs as possible and see what is going on behind the scenes. Two configuration options that GDAL picks up from the environment are useful here: gdal’s debug logs (CPL_DEBUG=YES) and logs for network calls through cURL (CPL_CURL_VERBOSE=YES). The output was verbose but these few lines from the cURL logs stuck out:
[30;1m [45;1m[1 of 1000] [0m [36;1mDEBUG(1) CPLE_None(0) "No error." AWS: AWS_ROLE_ARN configuration option not defined [0m
HTTP: Fetch(http://169.254.169.254/latest/api/token)
HTTP: libcurl/8.4.0 OpenSSL/3.1.4 zlib/1.2.13 zstd/1.5.5 libssh2/1.11.0 nghttp2/1.57.0
CURL_INFO_TEXT: Couldn't find host 169.254.169.254 in the .netrc file; using defaults
CURL_INFO_TEXT: Trying 169.254.169.254:80...
CURL_INFO_TEXT: Immediate connect fail for [169.254.169.254](http://169.254.169.254/): Invalid argument
CURL_INFO_TEXT: Failed to connect to 169.254.169.254 port 80 after 0 ms: Couldn't connect to server
CURL_INFO_TEXT: Closing connection
HTTP: Fetch(http://169.254.169.254/latest/meta-data/iam/security-credentials/)
CURL_INFO_TEXT: Couldn't find host 169.254.169.254 in the .netrc file; using defaults
CURL_INFO_TEXT: Trying 169.254.169.254:80...
CURL_INFO_TEXT: Immediate connect fail for [169.254.169.254](http://169.254.169.254/): Invalid argument
CURL_INFO_TEXT: Failed to connect to 169.254.169.254 port 80 after 0 ms: Couldn't connect to server
CURL_INFO_TEXT: Closing connectionNo error? AWS_ROLE_ARN not defined? Clearly, something was wrong and deeper exploration of GDAL source was warranted. One file, cpl_aws.cpp, governs the expected behaviors when trying to use the default credential chain as laid out by AWS. Here is the source in question as it was at the time: https://github.com/OSGeo/gdal/blob/release/3.7/port/cpl_aws.cpp#L834-L848. At first glance, this looks entirely reasonable. GDAL has always worked on other AWS services and the environment variable `AWS_CONTAINER_CREDENTIALS_RELATIVE_URI` is exactly what I’d expect.
Doubt, panic, etc. were all on the table at this point, so I threw a hail mary and printed out the environment fully expecting to see that I had somehow prevented the necessary environment variable from being set through container customization. What I saw instead was entirely new to me: `AWS_CONTAINER_CREDENTIALS_FULL_URI`. Searching the internet, I came across documentation that I’ll admit I still find a bit confusing. Apparently, under conditions the authors were either unaware of or didn’t feel the need to expand upon, sometimes a full URI would be provided instead of the more common relative URI that I’d always seen in the past.


How to facilitate large-scale data processing needs
Referring back to the source that governs the relevant behavior, I discovered that GDAL was missing a block of code to handle this possible scenario. I’ve used GDAL for years, as have many I know in the world of open-source GIS, and this is perhaps only the second or third bug I’d ever seen. So, I lodged an issue attempting to explain exactly what I’d uncovered. Within minutes, Even Rouault (https://github.com/rouault) – whose work on GDAL is expansive and surely underappreciated given the scope of activities it underwrites – had drafted up the fix suggested by my investigations and slated the bugfix for release in the then-upcoming GDAL version 3.8.2.
In the meantime, I hacked together a modified `entrypoint.sh` script for the custom container which used jq to set environment variables that would be picked up by GDAL in versions prior to the fix.
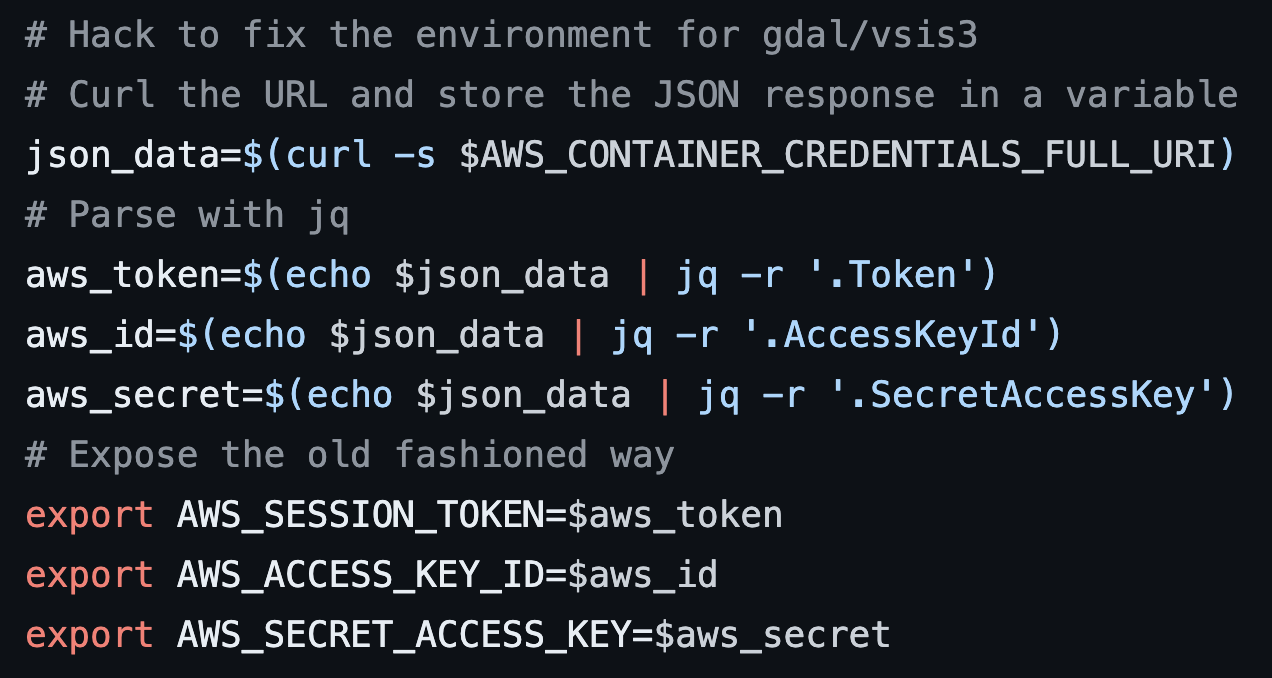
This hack works, by the way, but it is potentially problematic if jobs run for too long. A better bet would be to just build a newer version of GDAL. To this end, I’ve provided just that along with the terraform appropriate to set up your own EMR-Serverless cluster in this small project: https://github.com/moradology/gdal-emr-serverless
If your organization has use for large-scale data processing, it might just be cheaper and easier to manage than you think. We have quite a bit of experience with exactly these sorts of problems and some of the particular difficulties that make image processing at scale a unique challenge. Feel free to reach out if you’d like to know more or have challenges we can help you tackle.