At Element 84 we help groups rethink how they approach technology and are particularly focused on supporting migration to the cloud. As we moved from local hard drives to the cloud, there are things we took for granted when it came to file formats. On your own hard drive reads are cheap and latency is low. When you optimize for a hard drive you don’t need to worry about the number of reads required to access data. In the cloud, though, latency is very high but throughput is higher, so making lots of small reads is very expensive. To optimize data for the cloud we want to fetch lots of data with a small number of reads, while operating at scale where we can’t fetch everything.
Over the last few years, we’ve been working to understand the advantages and disadvantages of data access and use in the cloud and participated in a Cloud-Optimized Format study detailed here.
Regardless of selected format and compression algorithm, data providers should optimize files for partial access over HTTP using the Range header, which is the underlying mechanism used to retrieve data from cloud-based object stores but is also possible to use from a variety of systems, including on premises servers”
NASA Cloud-Optimized Format Study
Over the last 18 months, we have built on the work by USGS/HDF to access netCDF as Zarr. The big takeaways are that with a sidecar metadata record that includes byte offsets, a user can “access HDF5 format data as efficiently as Zarr format data using the Zarr library.” In other words, users can gain the cloud-optimized performance of Zarr while retaining the archival benefits of NetCDF4. The community is excited by Zarr, but there are some limitations that we are running into that deserve attention.
We’ll detail our approach reading a NetCDF4 archive—specifically data from from the NASA EOSDIS cloud archive—while retaining the performance and ease-of-use of Zarr, including some opportunities that could allow NetCDF4 to outperform Zarr in the cloud. There are three fundamental parts to any data access:
- Determine the location(s) within the file that contain the data
- Read the data from those locations
- Translate the data from raw byte values into something meaningful
In the cloud, the first two pieces—finding where data is physically located and transferring it—are where we have found the greatest need for optimization.
Optimization 1: Allow Reading of EOSDIS NetCDF Files from Zarr Python
We needed to optimize reads of NASA EOSDIS data, which is also primarily stored in NetCDF4. One step along that path is to quickly determine the offsets within the file that contain a particular area of interest. The USGS/HDF article does this by producing a sidecar metadata file in Zarr’s format that is augmented with byte offsets. Through convergent but unrelated evolution, OPeNDAP’s Hyrax Data Server needed sidecar metadata files for the same performance reason.
So we have NetCDF4 files + sidecar metadata records in DMR++. We produced a Zarr storage library that translates between the DMR++ format and the key/value pairs that Zarr expects—and suddenly Zarr could directly read NASA EOSDIS data without us needing to produce any new metadata.
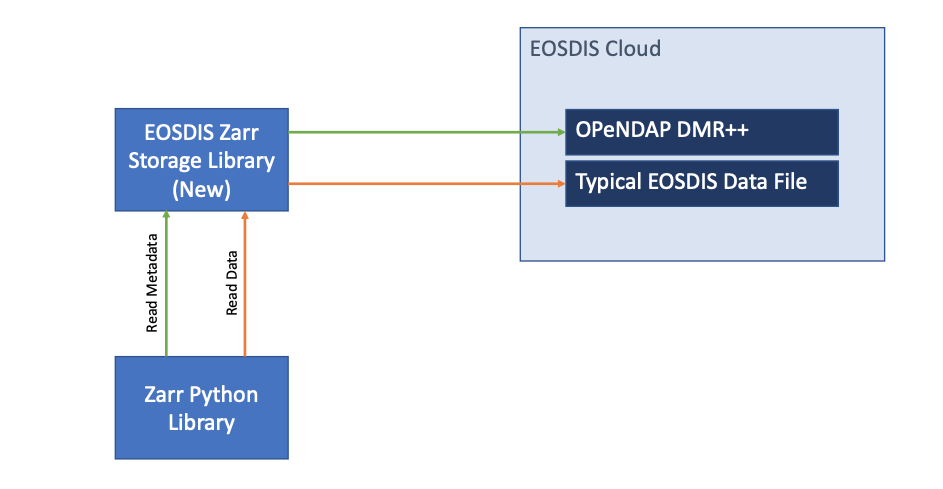
This applies the USGS/HDF work to a new dataset with different metadata, but there is still some optimization needed.
Optimization 2: Caching Redirects
As it stands, a single request through the Zarr library can make hundreds of individual access requests to the data URL. For each request, the archive may route the library through authentication handshaking and will ultimately redirect the library to a pre-signed S3 URL. This more than doubles the total number of requests that ultimately get made—and with naive handling can be 5 times the requests.
That final URL is valid for all of our data requests. We make an optimization where we fetch it once—following all redirects—and reuse it for the duration of the data accesses.
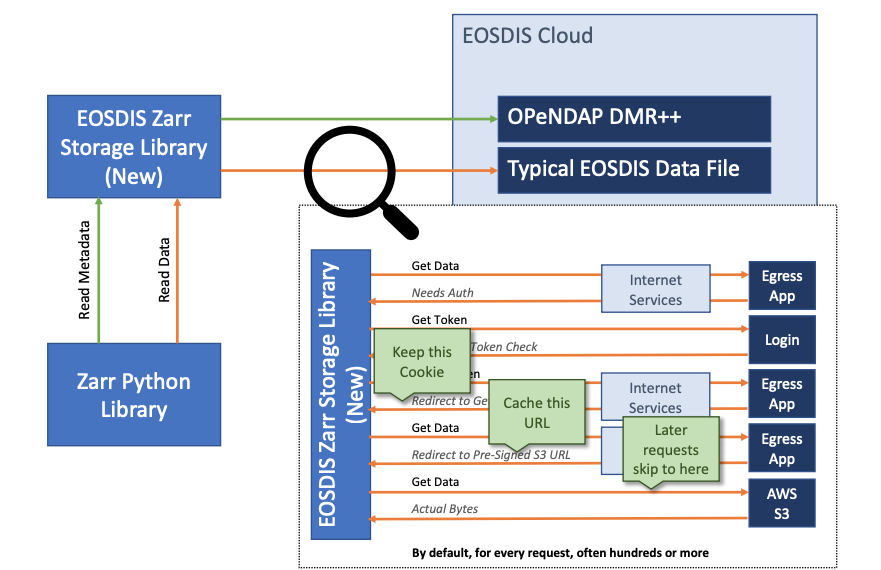
The big takeaway of this approach is that we avoid getting between clients and data.
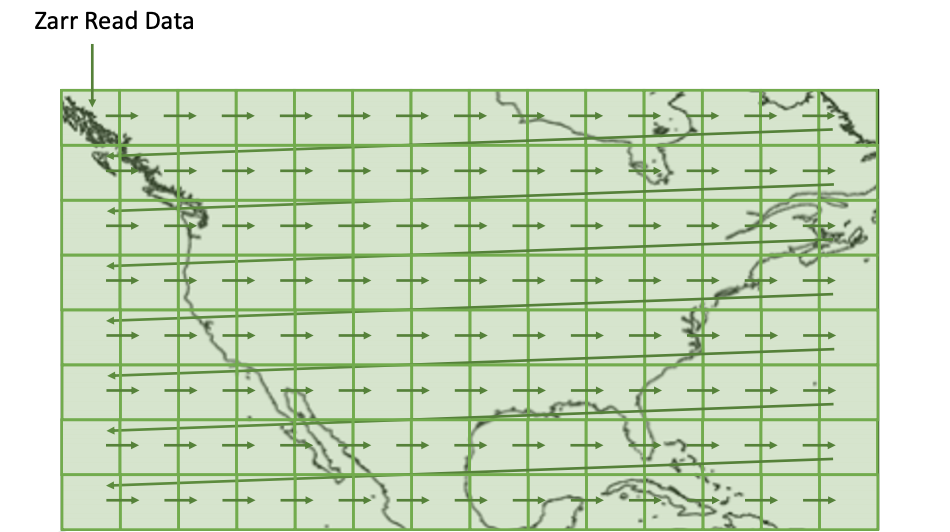
Optimization 3: Combine Requests for Near-Adjacent Ranges
Even with Optimization 2, there are still a lot of requests. Conventional wisdom says RECHUNK!, but this is an impractical approach for the data archive. However, data near each other in an array also tend to be near each other on disk. We identify and combine any near-adjacent reads into larger single-request reads, fetching more data at once. Interestingly, this is an optimization that can be made for data stored as a NetCDF4 file which could not be made using the default S3-based Zarr store.
This now allows us to make one slow read as described in optimization 2, followed by a smaller number of large, faster reads. The end result avoids iterating across an entire dimension in the array.
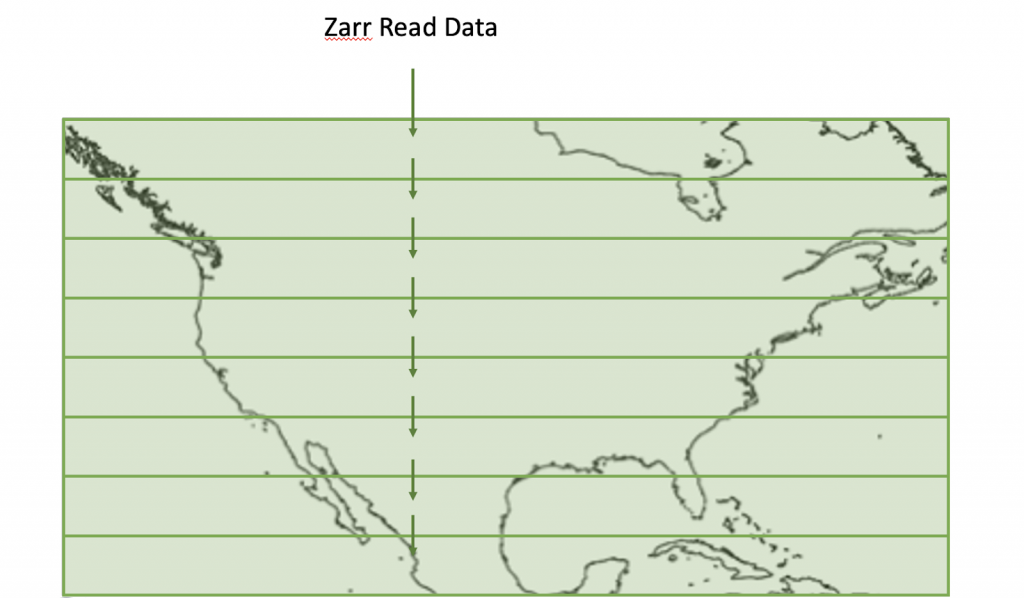
Optimization 4: Parallelize once we have an S3 URL
We take advantage of the ability to parallelize reads in the Zarr library and ensure our faster reads all happen at once.
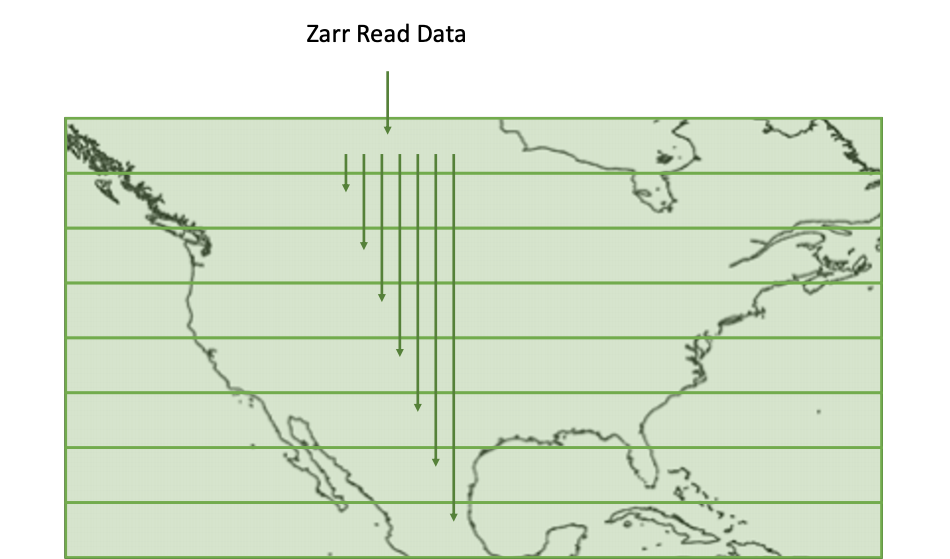
Optimization 5: Cache Outputs for Future Reads
Finally, the single fastest way we can fetch data is to avoid fetching it at all, so we cache data we have fetched to avoid re-fetching it on subsequent operations.
Conclusions
Cloud access demands read latency optimization.
- Combine many smaller reads into fewer larger reads (metadata and data)
- Skip expensive network actions such as auth and redirects, if possible, via cookies and caching
- Parallelize reads
In summary, we found some easy wins in the realm of optimizations:
- Group file metadata, preview info, into a single or small numbers of reads and that allows you to figure out what else you need
- Fetch efficiently, only when needed, in parallel, avoiding unnecessary operations
The hard work for performance in the cloud, however, is data locality: organizing a file such that data likely to be read together are stored together. While some rules of thumb may exist, it is often highly use case dependent—where the optimum organization for analysis in one dimension is the worst for analysis in another.
As the NASA report concluded, “We find no one size-fits-all solution but offer some broad guidelines to inform choices for specific needs.”
The source code for this work is available on GitHub along with a notebook demonstrating its use.
Image credit: NASA Earth Observatory
