
Microsoft launched the Planetary Computer in April 2021, and since then Element 84 and others have worked with Microsoft to help maintain and improve the system. The Planetary Computer provides open access to petabytes of cloud-optimized geospatial data, and is built on the STAC specification and the open system of tools around that specification. In this post, we’ll walk through the components of the Planetary Computer and show how it is based on both cloud-optimized formats and the STAC spec, and how this work benefits the larger community.

Data catalog
The Planetary Computer Data Catalog is a petabyte-scale living archive of open geospatial data, hosted on Azure Blob Storage in Azure’s West Europe region. If you’re not familiar with Azure’s blob storage model, it’s roughly comparable to AWS S3. The Data Catalog currently holds over one hundred indexed datasets and tens of other non-indexed datasets. Datasets range in size from small, single GeoTIFFs all the way up to Sentinel-2 and Landsat. The Data Catalog includes earth observation data, modeled outputs, weather station records, and more. The data are freely accessible by the public, though most assets require a signed URL for access, acquired via the Planetary Computer authentication API.
When creating the Data Catalog, the team building the Planetary Computer (PC) added some value to the open geospatial data beyond simply making them freely accessible on Azure blob storage. First, by co-locating all the datasets in the same Azure region the PC allows complex, multi-dataset analysis to be performed without having to ship bits across regions and continents. Second, when adding datasets to the catalog, they are converted to the appropriate cloud-optimized format whenever appropriate. For example, multivariate NetCDF files are taken apart and converted to a set of Cloud Optimized GeoTIFFs (COGS), and those COGs are hosted alongside the source NetCDF and include in a STAC Item.
These cloud-optimized assets are used to drive our front-end, including our dynamic tiler used in the map-based data explorer, and can be leveraged by analysis tools that take advantage of their cloud-optimized layout. All of this conversion work is made public via Python packages in the stactools-packages Github organization, allowing others to check our work, or use our conversion routines theirselves. Finally, when working to incorporate new datasets into the Data Catalog, the metadata producers such as Element 84 often find little quirks or surprises with data format, documentation, or metadata. While the Planetary Computer chooses not to change the source data, the team often corrects problems while converting to cloud-optimized formats, or at least documents the surprising traits of a dataset so downstream users are aware.
API
While free access to the Data Catalog is a useful service, discovering and searching for data over space and time is an essential part of most analysis. The Planetary Computer has a STAC API, backed by a Postgres database, for doing this search and discovery. However, before we discuss the STAC API, it might be helpful to talk a little bit about how the Planetary Computer gets a new dataset into the database so it can be served.
Ingesting a new dataset

First, the Element 84 team does a detailed review of the dataset, during a step we call “research and requirements”. During this step, we determine a strategy for creating STAC metadata for the dataset, and decide whether we can and should convert the source data to a cloud-optimized format if it isn’t already in one. Once the research is done, we create a Python package in the stactools-packages Github organization. This package is responsible for creating STAC Items and Collections from the source data, and possibly additional ancillary metadata. These packages are publicly available for comments, bugfixes, and for use by others. Each dataset also requires some Planetary Computer-specific configuration, including rendering information for our data explorer front end. Once the stactools package and the Planetary Computer configurations are in place, we load the STAC items into the staging environment, and perform any cloud-optimized conversions required. Finally, datasets are released from staging to production on a roughly quarterly cadence. Once released, a dataset is available publicly through the Planetary Computer STAC API.
Using the STAC API
By providing a publicly available STAC API endpoint, the Planetary Computer supports a wide range of use-cases backed by the same infrastructure. First, the Planetary Computer explorer is a map-based interface built on the STAC API and a dynamic tiler called titiler.

$ pip install pystac-client
$ stac-client search \
https://planetarycomputer.microsoft.com/api/stac/v1 \
-c landsat-c2-l2 \
--intersects "$(cat geometry.json)" \
--datetime "2022-06-01/2022-09-01" \
--query "eo:cloud_cover<=10" \
> result.jsonIn this next example, we’re performing exactly the same query, but this time using a command-line interface provided by the pystac-client library. You can see how easy it would be to change out the collection id, for example, and perform exactly the same query on a different dataset such as Sentinel-2. This command-line interface can be useful for examining the attributes of the STAC metadata or for checking for the existence of data in a specific time and place.
from pystac_client import Client
geometry = {
"type": "Polygon",
"coordinates": [[
[-39.0, 66.0],
[-38.0, 66.0],
[-38.0, 67.0],
[-39.0, 67.0],
[-39.0, 66.0]
]]
}
client = Client.open("https://planetarycomputer.microsoft.com/api/stac/v1")
search = client.search(
collections=["landsat-c2-l2"],
intersects=geometry,
datetime="2022-06-01/2022-09-01",
query=["eo:cloud_cover<=10"],
max_items=10,
)
item_collection = search.item_collection()
assert len(item_collection) == 10Finally, the same query can be performed using the pystac-client Python API. This method is quite common in notebooks, where STAC queries are used to discover data for eventual loading and analysis.

For example, here’s a short code snippet showing how to display data from a single landsat scene in a notebook using the Planetary Computer API and odc-stac. You’ll notice on line three that we sign the item using the Planetary Computer API. Under the hood, this step requests a new Shared Access Signature (SAS) from the Planetary Computer authentication API, and modifies all asset hrefs with that SAS to allow for authenticated requests. Note that this signing process is, for now, purely a request audit mechanism; you don’t need an account to get a signed url. Notice too how we’re using odc-stac – this is a library that can take a set of STAC items and convert their assets into an xarray, which is a powerful data structure widely used in scientific computing. We will dive deeper into using odc-stac and xarray in a later post, based on this notebook.
Planetary Computer Hub
Now we’ve seen how the Planetary Computer STAC API is both publicly accessible, and is used to drive the data explorer while enabling search and discovery by downstream users. The Data Catalog and the API are all that you need to use the Planetary Computer yourself in your scripts and workflows. However, if you want to use pre-configured compute resources co-located with the Data Catalog, you want to use the Hub.
The Planetary Computer Hub requires account approval before you can use it. You can request access from the Planetary Computer website. The Hub comes pre-configured with a variety of environments, supporting a variety of use-cases. The Python Hub option is based on the Pangeo notebook environment, and all the environments have been customized to work with the latest and greatest packages in the STAC ecosystem.
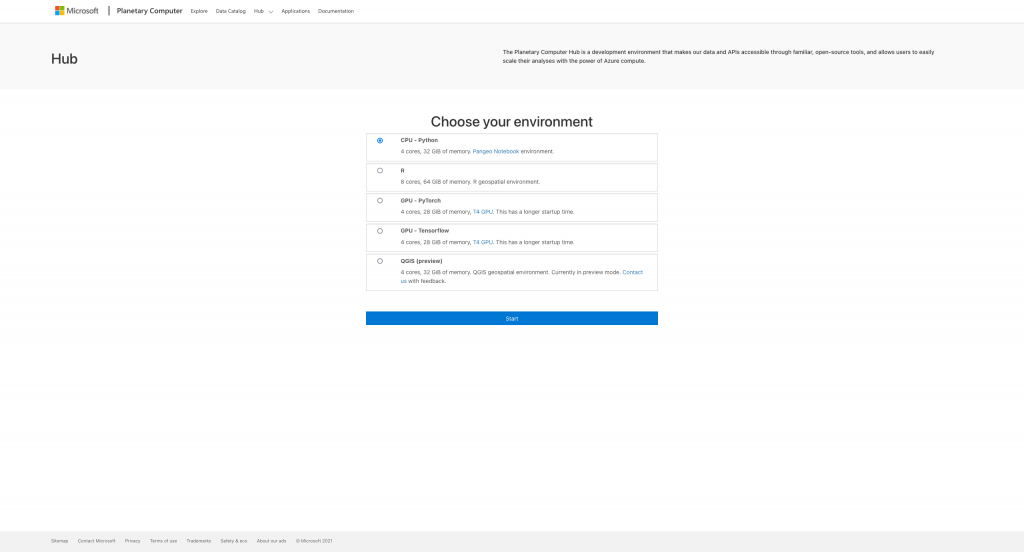
The Hub comes with a wide range of example notebooks and tutorials, including a walkthrough notebook for every available dataset. By providing an environment that is co-located with the data, you can perform complex analysis without moving bits out of the region. Check out the Planetary Computer Documentation for more information.
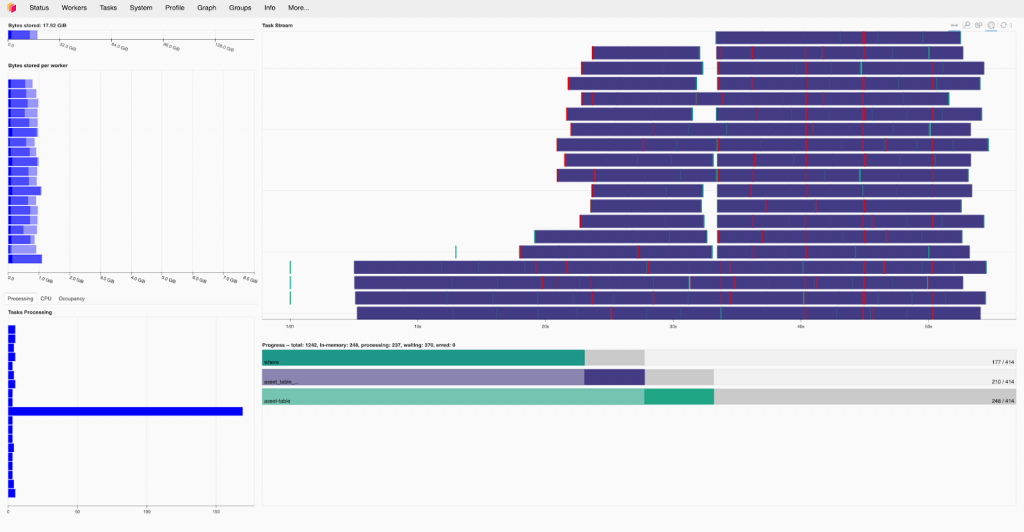
If you really need to scale your analysis, the Hub also provides a Dask gateway for distributing your work among Dask clusters. Dask is a parallelization framework that can be used under the hood in data structures such as xarray to distribute computing among a set of workers – it can also be used directly to schedule and execute work.
Microsoft’s Planetary Computer’s investment in open software and open data
Open source tools and principles greatly influence the continued development of the Planetary Computer. Next, we’ll highlight a few open source pieces that are key components to the Planetary Computer architecture.
| Name | Description | Language | Github |
|---|---|---|---|
| PySTAC | API for working with STAC Items, Collections, and Catalogs | Python | stac-utils/pystac |
| pystac-client | API and CLI for querying STAC APIs | Python | stac-utils/pystac-client |
| stac-fastapi | STAC API implementation that drives the Planetary Computer API | Python | stac-utils/stac-fastapi |
| pgstac | Postgres schemas and functions for a STAC database | PLpgSQL | stac-utils/pgstac |
| titiler | Dynamic tiling | Python | developmentseed/titiler |
PySTAC is a Python API for working with STAC objects and is the defacto software implementation of the Item, Catalog, and Collection specifications. It’s a foundational library used throughout the Planetary Computer system and in the STAC ecosystem. pystac-client is a Python API and command-line interface for querying STAC APIs, and is heavily used in the Planetary Computer example notebooks. stac-fastapi is a STAC API implementation that drives the Planetary Computer’s API. titiler is a very cool library that creates dynamic tiles and mosaics from geospatial data, and drives the Planetary Computer data explorer. Finally, pgstac is the schema and functions for working with STAC in Postgres. This is just a short list of some of the libraries that Microsoft has supported, either directly or indirectly, as a part of Planetary Computer development, but demonstrates the organization’s commitment to incorporating open source elements.
In addition to software support, the Planetary Computer project also has helped drive forward the STAC specification, its extensions, and its best practices. By investing in open software and public documentation, the Planetary Computer has enabled reproducible science and equitable access to the resources and data needed to produce meaningful research that benefits our world. At Element 84, we helped take the classification extension to its initial release, which was an improvement over existing methods of providing semantic meaning for data, for example in land cover datasets. We also have a lot of lessons learned, as we’re one of the large public STAC APIs out there, and we do our best to contribute our lessons back in the form of best practices or discussions in the STAC specification github repository.
For more about the Planetary Computer
In later posts, we’ll walk through more technical use-cases of the Planetary Computer data and Hub. If you have questions, please reach out!
This post was developed from the notes of the talk I gave at PECORA 2022 in Denver, Colorado. The slides for that talk are available here.
