If you are working with geospatial data visualizations you have probably heard of Cloud Optimized GeoTIFFs and may also have heard of the Meta Raster Format. These formats both provide efficient access to visualization data and have similar goals. The popular GDAL library supports both. So what are the differences, and when would you choose one over the other?
The Impetus
Why do we need either of these formats? Because images derived from geospatial data (and satellite images in particular), tend to be HUGE. And often a user is only interested in a small portion of an image, say, some small region of an image of the entire Earth. Downloading an entire image just to view a small portion of it is a waste of time and resources. Therefore, there is a need for image formats that support partial downloads. This is where Cloud Optimized GeoTIFFs and the Meta Raster Format come in.
Cloud Optimized GeoTIFF
The Geospatial Data Abstraction Library (GDAL) introduced Cloud Optimized GeoTIFFs (COGs) . They are not a new format; they are simply GeoTIFFs that have an internal organization that supports efficient access via HTTP. This internal organization, combined with an HTTP feature called GET range requests, allows a client to retrieve only the portion of the file that it needs.
Organization of Cloud Optimized GeoTIFFs
There are two components to the internal organization of COGs, tiling and overviews.
Tiling
Typical raster images store data row by row, as shown in Figure 1. So the client must read the whole file to get a piece of the image.
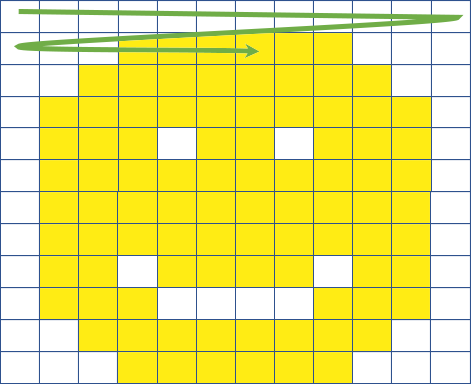
COGs store image data in tiles as shown in Figure 2. With tiling, only the tiles covering the area of interest need to be read.
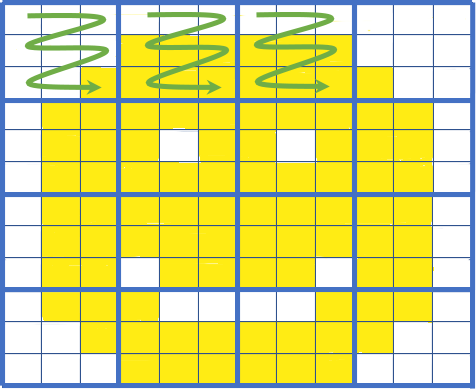
Overviews
Overviews are downsampled versions of the original image as shown in Figure 3. They represent “zoomed out” versions of the image.

Multiple overviews can be stored in a COG to match multiple zoom levels. Overviews are stored tiled just like the original image. So an application that supports zooming only needs to retrieve the tiles for the overview associated with the given zoom level.
HTTP GET range requests
HTTP 1.1 introduced support for range requests. Range requests allow a client to request only a portion of an HTTP message from a server. This is useful for applications serving large media files such as videos in which the client may only want a portion of a file, for instance to resume play after pausing.
HTTP servers are not required to support range requests. A server indicates support for range requests by returning the header Accept-Ranges: bytes. Then the client is able to make requests for specific byte ranges within the file. In the case of COGs, this allows the client to request individual tiles or tile ranges without downloading the entire file. Even if a server does not support range requests, a client can still work with the GeoTIFFs, albeit by downloading entire files.
Meta Raster Format
The Meta Raster Format (MRF) was introduced by NASA’s Jet Propulsion Laboratory (JPL). Like COGs, MRF files store imagery in a tiled format that allows for quick access to individual tiles. Also like COGs, MRFs store multiple resolutions of the image to facilitate zooming.
Meta Raster Format “files” actually consist of three sub-files, the MRF file, the data file, and the index file.
The MRF File
The MRF file, with the suffix “.mrf”, is an XML file that provides metadata about the image and the tiles, such as compression type, projection, etc. An example is given below:
PJGs and PPGs
The data file is a single file that stores the actual tile images. Tiles in an MRF are self-contained images, either JPEGs or PNGs. If the tiles are stored as JPEGs, the suffix for the data file is “.pjg”, short for “pile of JPEGs”. If the tiles are stored as PNGs, then it is a “pile of PNGs”, with suffix “.ppg”.
Index Files
The index file (suffix “.idx”) stores the byte ranges of each tile in the data file. These are stored as a list of 64 bit offset and length pairs as shown in Figure 4.
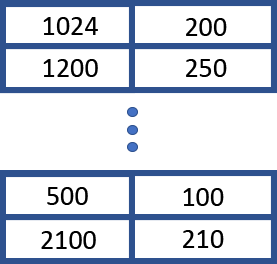
The format supports sparse data (empty tiles) efficiently by storing a single “empty tile” as the first tile. Any missing parts of the image reference the “empty tile”. This allows index files to be stored as sparse files since many of the tiles in an MRF may be empty. An example is an image from a single satellite orbital pass.
Since the index file keeps track of tile positions the tiles in a data file need not be stored sequentially . This allows updates to data files to append the data to the end of the file. Then the index file is updated to point to the new version of a tile. This makes updates to MRFs very efficient and is very useful for incremental updates, say for near-realtime data.
In general there is less performance overhead for reading and writing MRFs as compared to COG. There is also increased flexibility for the way an MRF is generated. The cost is a more complicated format and the need for the server to understand and support index files. Also, index files can become huge if they are stored on a file system that does not support sparse files. Notably, S3 does not support sparse files.
When to use MRFs vs. COGs
So when should we use MRFs and when should we use COGs?
The primary difference between the two comes down to this: MRFs put the burden on the server, whereas COGs put the burden on the client. A tile server using MRFs needs to use the index file to efficiently retrieve tile data from an MRF, which increases the complexity of the server. On the other hand, because the server has to know more about MRFs, it can use this information to provide further optimizations like tile caching.
A simple HTTP server that supports HTTP GET range requests can serve COGs, but the client needs to keep track of the byte ranges it wants to retrieve from the image. With MRFs, the client can simply request tiles by number, or even by specifying a geographic bounding box / zoom level that the server can use to determine which tiles to return.
The simpler nature of serving COGs probably makes it more “cloud friendly” in that S3, Google Cloud, etc. support GET range requests and scale really well. And there is no need for support for sparse files. So applications that are run on the client side that need to access large data sets with little server support are a good fit for COGs. On the other hand, applications that require many file updates and additional server functionality (such as the Global Imagery Browse Services (GIBS)) are better suited to MRFs.
So in conclusion, if you want to make a large inventory of big images that support efficient partial downloads with minimum effort, and you are willing to leave the work up to the client, use COGs. If you want to build a sophisticated service that provides tiled imagery search services, MRFs are a better choice.
